Tip
一篇综述,请教师兄关于 MC 内容的时候师兄给的,主要说的是偏应用的 MC
为了面试的时候对 MC 有个大概的了解,临时抱的佛脚
问题介绍
Propositional Model Counting (MC) 即命题模型计数(SAT)是计算一个 CNF 公式 中有多少个解(即 model)
与 AllSAT 的区别
AllSAT 要求 枚举 (Enumerate) 所有满足公式的变量赋值
MC 只要求找到有多少组满足公式的赋值
AllSAT 可以通过知识编译技术来做到,将 CNF 转化为 d-DNNF 或者 OBDD,在这个上面去枚举即可
研究动机
尽管模型计数器的性能在学术竞赛(如模型计数竞赛)中得到了广泛评估,但这些竞赛的基准测试集通常是人为构造或特定领域的,可能无法全面反映计数器在真实应用场景中的表现。
Question
当前最先进的模型计数器在处理来自现实世界的应用实例时,其可扩展性(scalability)究竟如何?
Benchmark
- 将贝叶斯网络(Bayesian Networks)的推理问题编码为模型计数问题
- 网络可靠性:计算一个给定网络在边/节点可能失效的情况下,保持连通的概率
- 神经网络验证:验证神经网络的健壮属性(例如,对抗性扰动),通常可规约为模型计数问题
- 软件验证与测试:程序中的符号执行、路径计数、漏洞检测等问题
- 密码学与分析:分析密码算法的安全性,如寻找哈希函数的碰撞、评估密码原语等
- 程序合成:从输入-输出示例或规约中自动生成程序,搜索满足条件的程序空间
- 产品线配置:在具有大量可选功能的软件产品线中,计算有效产品配置的数量(Linux 内核配置)
- 信息流分析:验证程序是否存在隐秘信道,计算可能的信息泄露量(量化信息流分析)
- 计划与调度:计算在给定约束下可行计划的数量
- 组合优化:计算满足特定组合结构(如拉丁方、图着色)的对象数量
- 电路设计、形式化方法
记号与预定义
投影模型计数
投影模型计数是标准模型计数问题的一个重要变体。在投影模型计数中,我们只关心对公式中一个特定子集的变量(称为“投影集”)进行模型计数。
投影模型计数为什么比完全模型计数更难
完全模型计数 是一个 问题,投影模型计数 是一个 问题
- 完全计数:数一个房间里所有人的确切数量
- 投影计数:数这个房间里有多少个不同的姓氏
从求解器角度来看:
D4(精确知识编译器):它在完全计数模式下非常强大,因为它能找到一个高效的、支持多项式时间计数的表示。但当切换到投影模式时,它必须执行“聚合”操作,这通常会导致其内部编译过程产生指数级更大的中间结构,从而性能骤降或内存溢出。这说明预处理和编译无法绕过投影聚合带来的根本性结构破坏Ganak和ApproxMC:它们可能表现得相对好一些,尤其是当投影集P很大(接近完全计数)时。这是因为它们的算法(如基于哈希的计数)可以相对直接地修改为只对P进行哈希。然而,正如之前所述,这种修改破坏了均匀性假设,导致效率下降。论文中它们在某些实例上表现良好,在另一些上则很差,这反映了投影集P与隐藏变量H之间相互作用的结构敏感性
现代求解器技术支点
独立支持集 (Independent Support)
给定一个 CNF 公式 ,其变量集合为 ,若 的一个子集 满足:
- 对于任意两个赋值 ,若其在 上的所有变量赋值一致() 那么有 ,我们称 是 的一个独立支持集
独立支持集的作用如下:
- 将投影计数转化为完全计数:假设我们要对变量集 (投影集)进行计数。如果我们能找到公式 的一个独立支持集 ,并且
I是P的一个子集,那么:- 因为
I是独立支持集,所以每个对I的赋值最多对应一个完整模型。 - 于是,对
P的投影模型数 就等于 对I的完全模型数(因为I是P的子集,对I的赋值自动就是对P的赋值的一部分,而P \ I部分的值被唯一确定,不会产生新的投影)。
- 因为
- 大幅减少计数维度
一个比较出名的预处理技术 就基于独立支持集来做的
Note
预处理在 MC 中十分重要,在传统 SAT 求解中,大部分时间都在搜索上,比如 3600s 搜索可能就 10s+ 的预处理(可能有点夸张),但是在 MC 中可能是预处理 2000s 求解 1000s
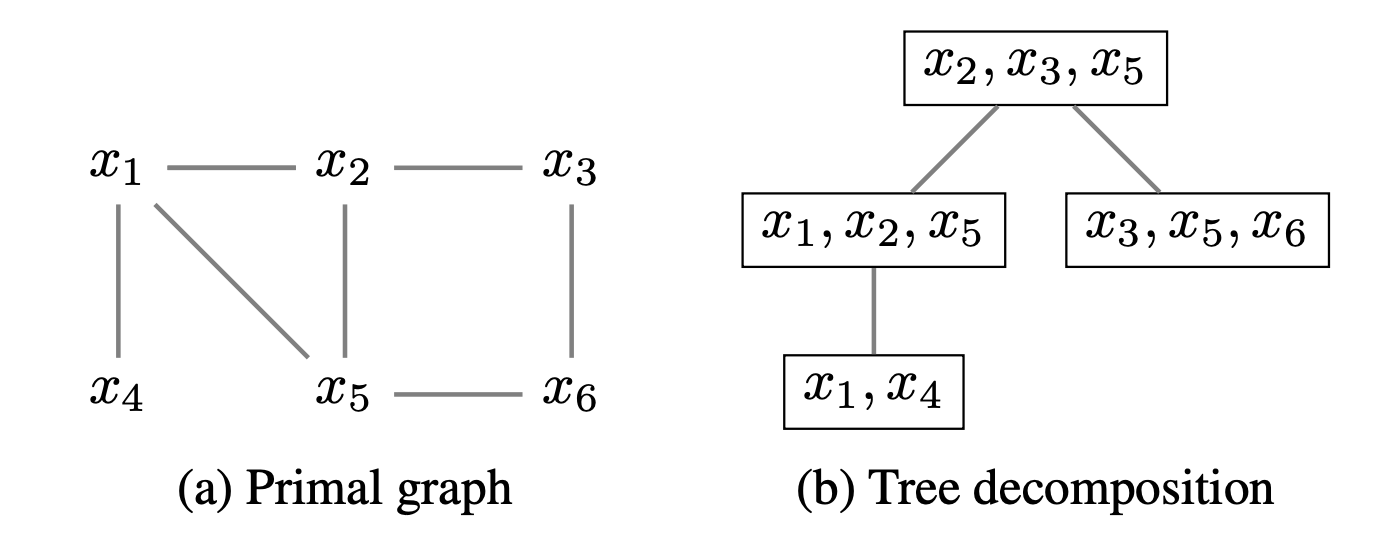
树分解 (Tree Decompose)
树分解是指将一个图分解为一棵树,其算法如下(带启发式):
- 将 CNF 建模为原始图(变量为节点,如果两个变量出现在同一个子句中,则它们之间有边)
- 对于图中的顶点,我们按照度的大小,从小到大排序,得到序列
- 若图上还有顶点,我们做以下循环,否则到第 7 步
- 创建一个新包 (bag) ,取出 的第一个变量 ,将 以及其图上的邻居都放入 中
- 将 的邻居之间连上边(如果不存在),然后从图上删去 及其相关的边
- 回到第 3 步
- 对于产生的所有 ,我们按照它们之间共享顶点的关系连接起来即可
一个简单的例子如下所示,变量消除的顺序为 :
Attention
树分解的形式有很多,一般而言,我们期望树宽最小化
树宽 (Treewidth)
当我们把图进行树分解后,我们定义树宽为
因此,一个最优的树分解就是树宽最小的树分解,即 ,这个问题是 NP-Hard 的,其本质难点就在于寻找最优的消元顺序
树宽是算法效率的理论保证和实际指导,尤其对精确计数至关重要:
- 动态规划的理论基础:假设我们已经得到了一个树分解,并将其转为有根树。DP 的过程是自底向上进行的,通过叶子节点向根进行 DP,记录合法的模型数。复杂度为 ,其中 为树宽。
- 指导求解器设计与启发式策略:
- 变量消除顺序:许多求解器(如
D4的编译器)在内部使用一种称为“消去序”的策略。寻找一个能产生最小中间子句的消去序,本质上等价于寻找一个最小树宽的树分解。好的变量顺序能防止动态规划表爆炸。 - 分解方法:像
DPLL搜索结合缓存/记忆化 的策略,其有效性直接依赖于公式的树宽。树宽小意味着在搜索过程中,需要缓存的部分赋值组合(即“分离集”)的数量是可管理的。 - 问题可解性判断:如果一个实例被检测出具有高树宽,那么精确计数器(如
D4)可能会提前预见到动态规划表会爆炸,从而选择回退到其他策略(如基于搜索的计数)或直接放弃。
- 变量消除顺序:许多求解器(如
- 连接独立支持集:树宽和独立支持集可以结合。如果一个公式的独立支持集 很小,并且公式在 上的“投影”结构具有低树宽,那么对这个公式进行投影计数将会异常高效。
Info
很多问题的 非常大(例如 ),导致 变成天文数字,传统的树分解算法直接失效。即使我们不能直接用树分解求出答案,我们也可以利用树分解的结构信息来指引搜索方向。 我们可以通过树分解的结构化信息,来为求解器的分支变量选择启发式做贡献: 其中:
- (Activity): 变量活跃度(VSIDS 常用指标),反映了变量在最近的冲突或推理中出现的频率;
- (Frequency): 变量在公式中出现的原始频率;
- : 寻找包含变量 的所有“包”(Bag)中,离树根最近的那个距离(归一化后的距离);
求解器分类
Compilation-based Exact Model Counters(CC)
精确模型计数,目前主要有两类主要技术:
- 基于知识编译:将输入的 CNF 公式编译成一种确定的、可多项式时间查询的数据结构(如 d-DNNF, SDD, FBDD)。一旦编译成功,计数可以在线性时间内完成。代表性工具:
D4,SharpSAT-TD,c2d。 - 基于成分分解:利用公式的结构(如树宽)进行递归分解和动态规划计数。
Hashing-based Approximate Counter(AC)
近似模型计数,在可接受的概率误差内,高效地给出模型数量的近似估计值。主要通过基于哈希的随机化算法,通过向原公式中添加随机哈希约束,将解空间均匀地“切片”,然后通过检查切片是否为空来估算总数。代表性工具:ApproxMC, Ganak, F3。
互补性
- 基于编译的精确计数器在公式树宽较低、结构性强的实例上表现卓越。
- 基于哈希的近似计数器在公式变量数多、但哈希约束易于求解的实例上优势明显。