起因
浏览了很多排行,调研了很多框架,但是都没找到很满意的 RAG 框架用来结合 Obsidian 做个人知识库:
- 比如 HayStack 感觉非常客制化,不是开箱即用
- RagFlow 开箱即用但是我是 Macbook Air,达不到要求
又找了一些 Obsidian 的插件,但是要么没办法配置自己的 API,要么不支持 RAG,要么很久没有更新了
所以最后还是退回了这个 obsidian copilot插件,可以配置 DeepSeek ,同样也支持 RAG(这也是我唯一需要的功能)
Cite
大部分步骤参考 此篇文章
LM Studio
首先我们需要一个模型来将知识库向量化,这个模型是跑在本地的大模型,用于将知识库内的文件向量化
这里我们使用 LM-Studio 来运行本地大模型,安装十分简单:
brew install lm-studio打开后,我们在其中随便选择一个算 embedding 的模型(按照下载量即可),例如这里选择的是 Qwen
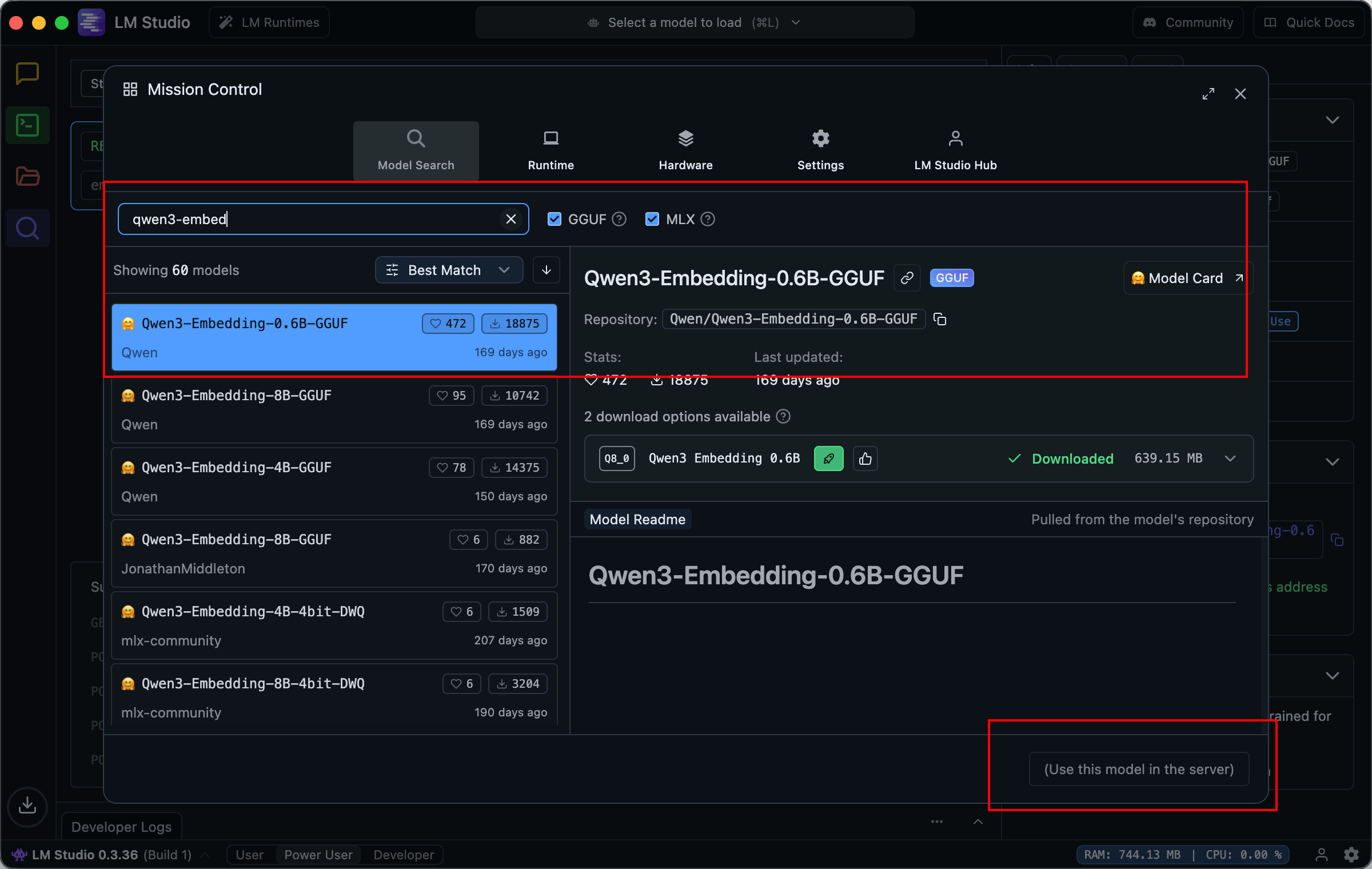
下载完成后,运行这个模型,然后牢记这个字段:text-embedding-qwen3-embedding-0.6b
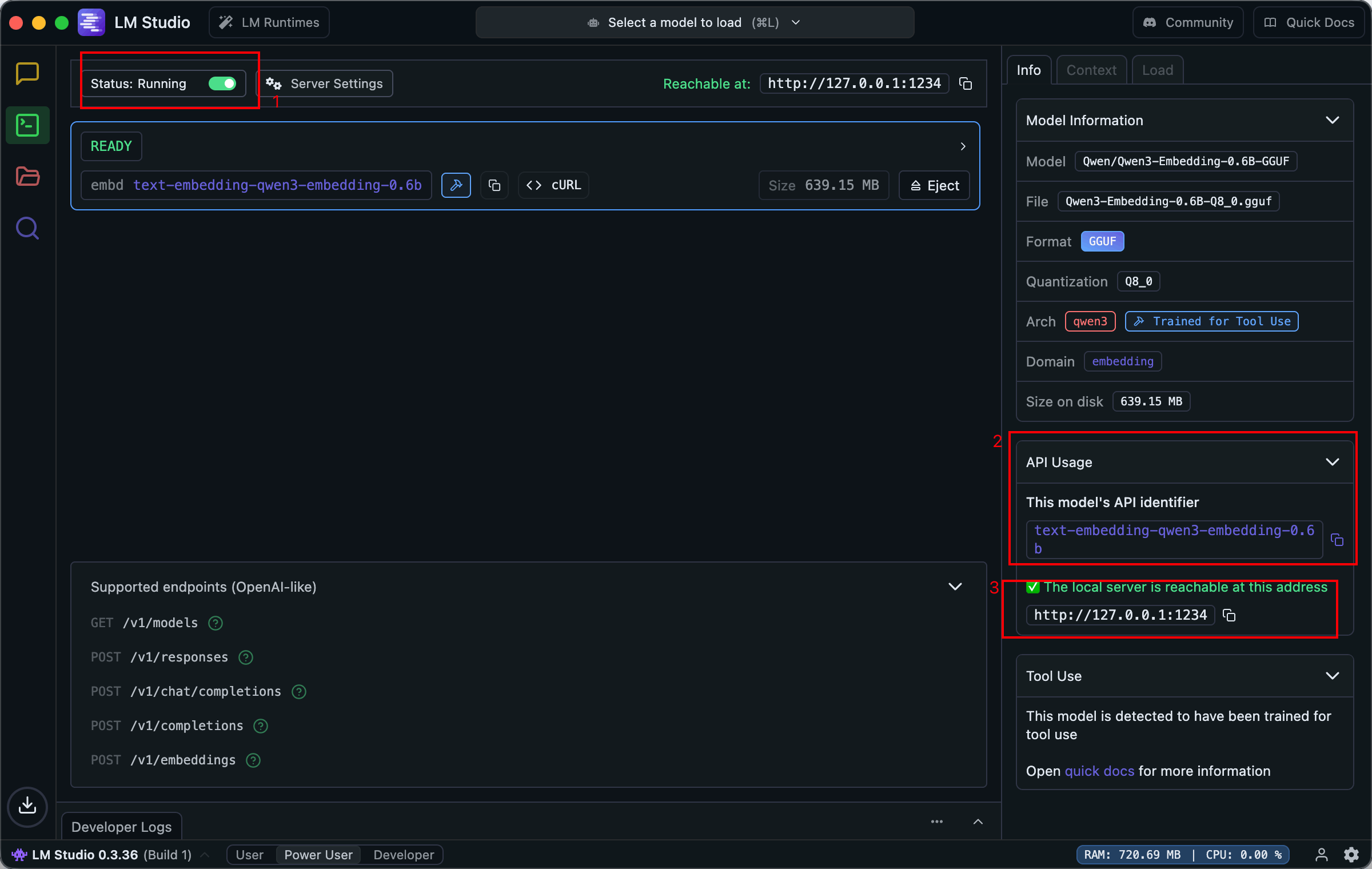
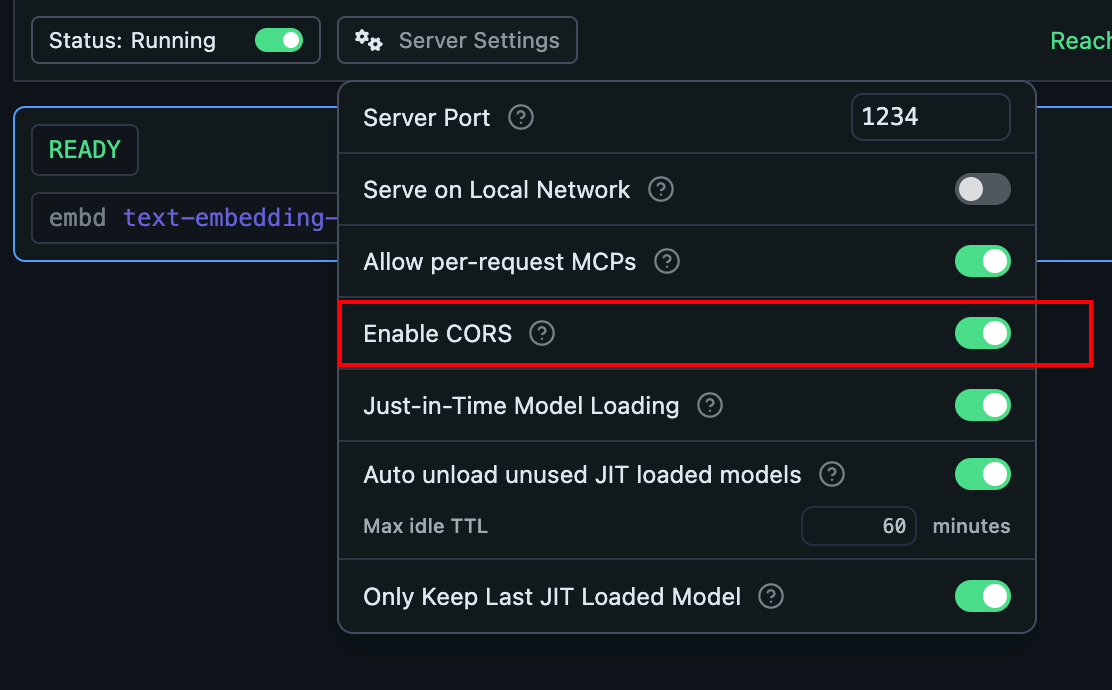
我们还需要将跨域请求勾选上:
插件配置
打开 Obsidian 中 Copilot 的设置,首先我们添加模型:
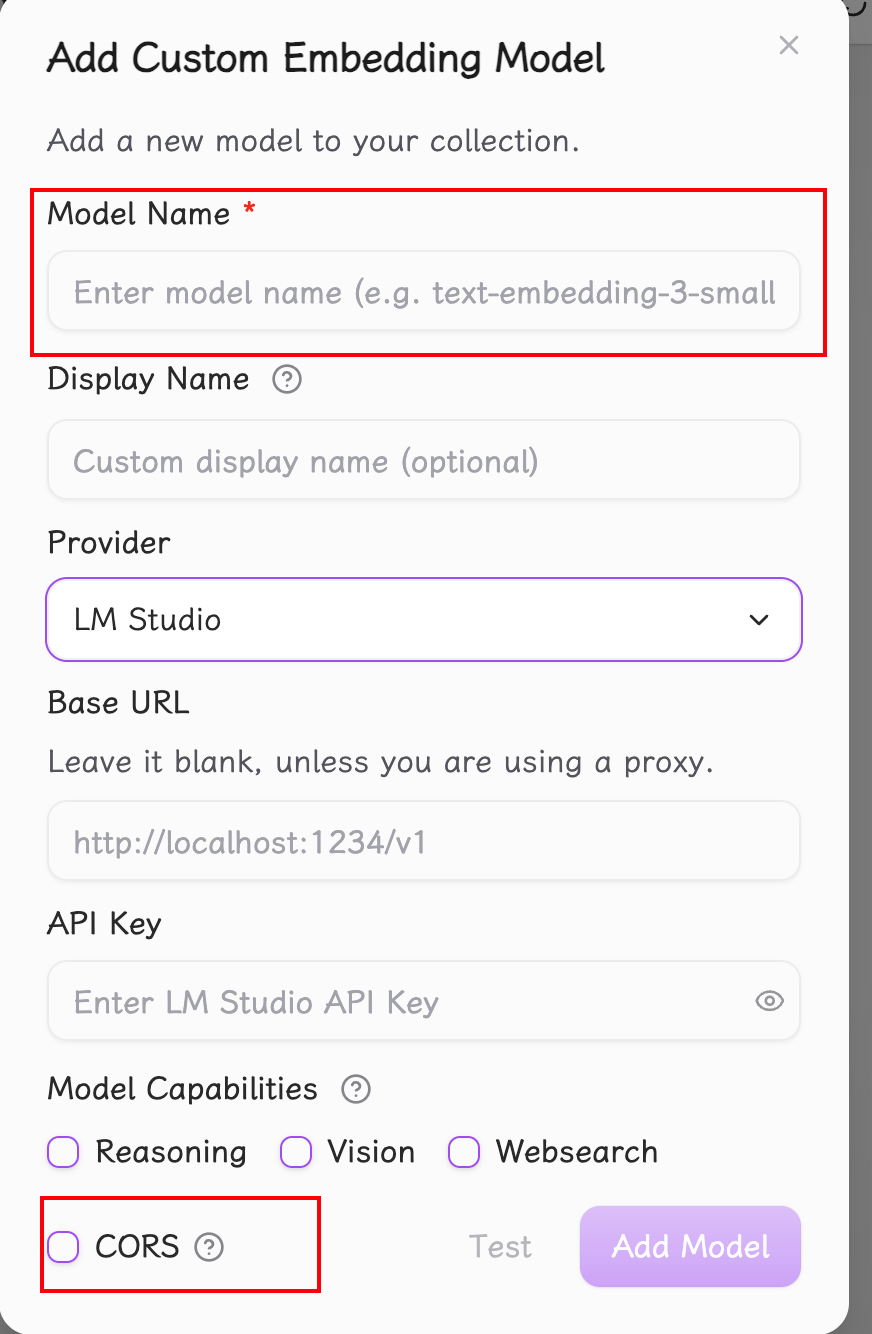
这里,Model Name 填入上文中提到的,例如 text-embedding-qwen3-embedding-0.6b ,并勾选上跨域请求
然后在 QA 处配置如下:
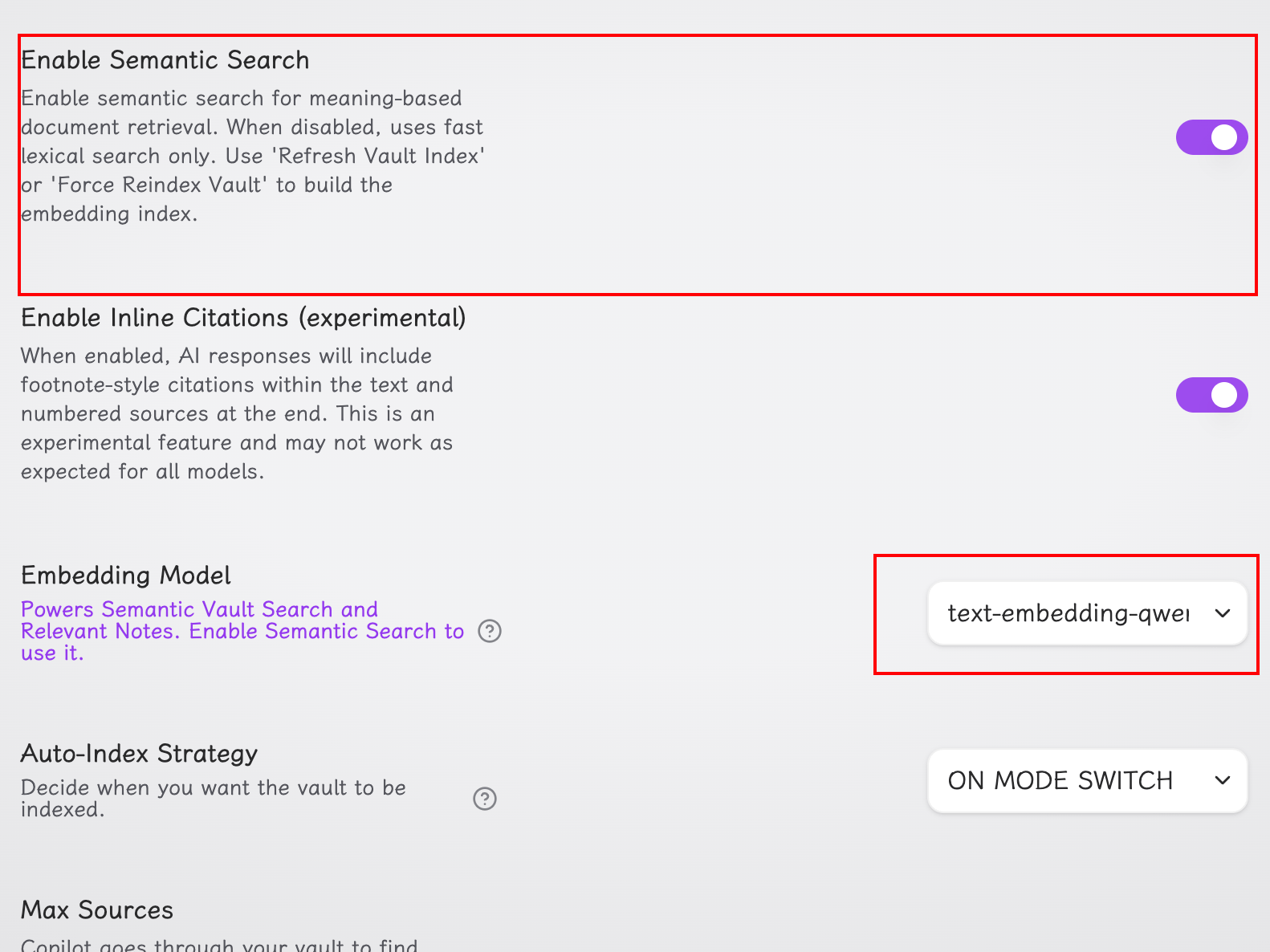
最后,我们打开对话框后,将模式切换到 vault QA 后即可开始使用
Attention
在第一次打开时会进行索引,记得把需要排除的文件删除,在
QA这个下面可以配置,否则可能会很大,跑起来也比较慢,毕竟是轻薄本(
使用
Note
在开启了
vault QA后,本地大模型需要一直跑着以提供支持,但是负责问答的大模型是通过 API 配置的,例如我这里是deepseek-reasoner
在每次加入新的文件后都需要刷新一遍数据库,以获得更好的支持
使用起来十分简单,例如(当然这里的问题是随便选的一个提示词):
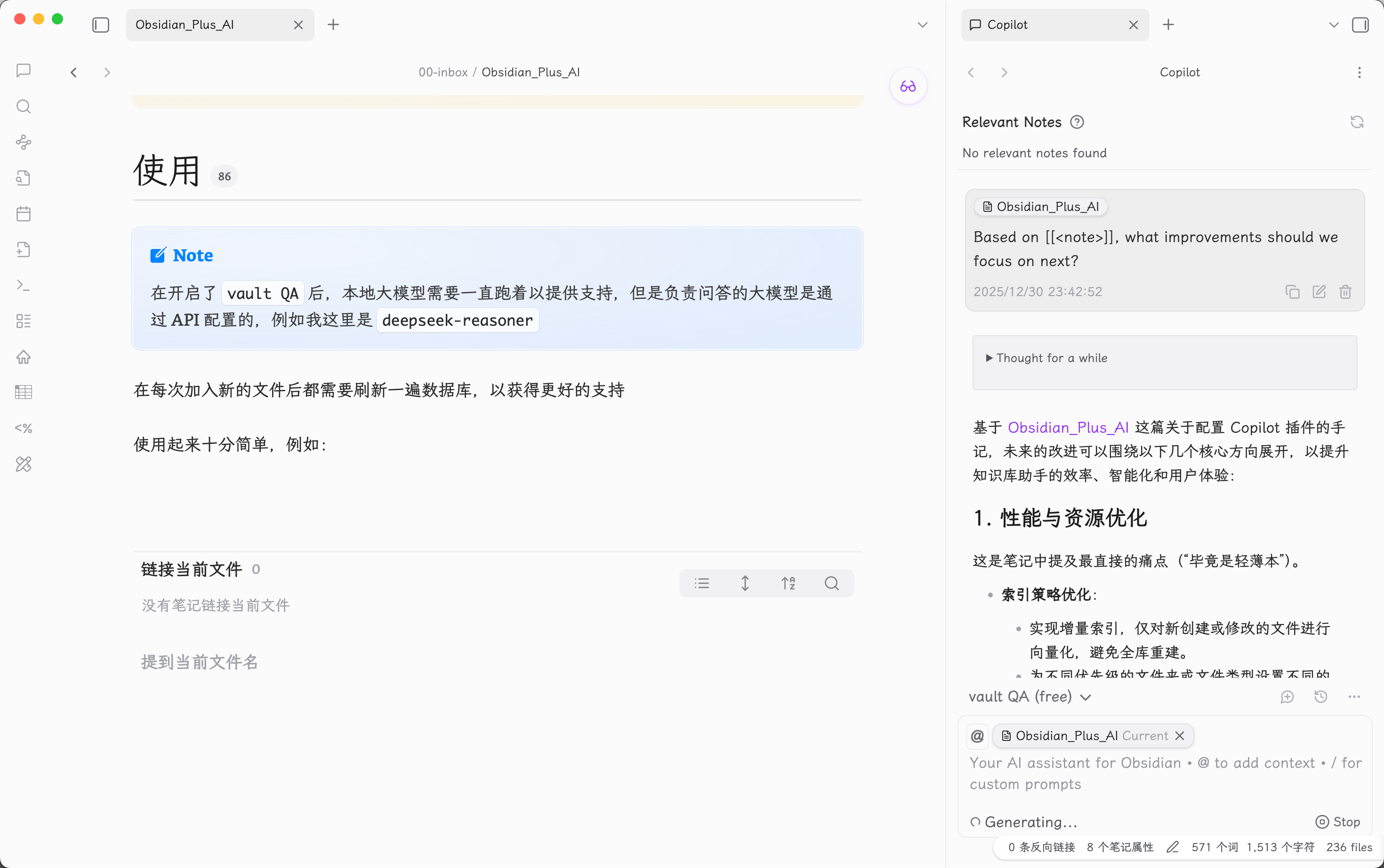
提问后,我们还可以打开他自动列出的关联笔记,帮助更好的联想与总结: